Module 7: Aurora Assignment
Problem Statement: You work for XYZ Corporation. Their application requires a SQL service that can store data which can be retrieved if required. Implement a suitable RDS engine for the same.
While migrating, you are asked to perform the following tasks:
- Create an AuroraDB Engine based RDS Database.
- Create 2 Read Replicas in different availability zones for better infrastructure availability.
1. Launching an AuroraDB Instance:
Step 1: I logged into the AWS Management Console and navigated to the RDS service.
Step 2: In the RDS Dashboard, I clicked on the “Create database” button.
Step 3: I chose “Amazon Aurora” as the database engine and selected the edition suitable for my needs. Aurora offers two types: MySQL-compatible and PostgreSQL-compatible. I went with the MySQL-compatible edition.
Step 4: In the “Templates” section, I picked “Production” to ensure a multi-AZ deployment with high availability.
Step 5: I provided the necessary details such as the DB cluster identifier AuroraDatabase, master username, and password.
Step 6: In the “DB Instance Size” section, I chose the desired instance type based on the performance needs.
Step 7: For availability, I selected “Create an Aurora Replica or Reader node in a different AZ”
Step 8: I configured additional settings like the VPC, security group (opening port 3306), and database name. Enabled “Public access”
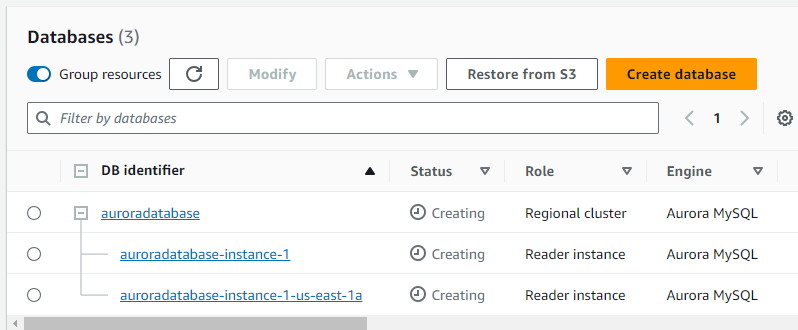
Step 9: Once all settings were in place, I clicked on the “Create database” button.
 “
“
2. Creating Read Replicas:
Step 1: Post the activation of the AuroraDB cluster, I clicked its identifier link in the RDS dashboard to dive into its specifics.
Step 2: Within the cluster details page, I located the “Actions” dropdown menu.
Step 3: From the dropdown, I selected “Add reader” to initiate the process of setting up a read replica.
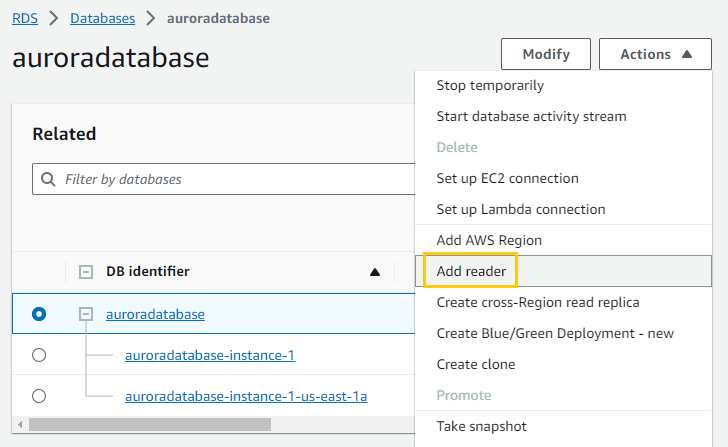
Step 4: When I began setting up the first read replica, Aurora gave me an option to choose between two Availability Zones: ‘a’ and ‘b’. Since the default reader was already in AZ ‘a’ and the writer was in AZ ‘b’, I decided to balance the read load by placing this replica in AZ ‘a’.
Step 5: Moving on to the second read replica, I again had a choice between AZ ‘a’ and ‘b’. To ensure a balanced distribution of read load and provide redundancy in both zones, I placed this replica in AZ ‘b’, the same zone as the writer instance.
With the above steps, I successfully set up an AuroraDB cluster with two read replicas spread across different availability zones, ensuring high availability and fault tolerance.
Test the Connection: